
There was a time that every Linux kernel hacker loves Android. It comes with a kernel from stone-age with merely any exploit mitigation. Writing exploit with any N-day available was just a walk in the park.
Now a days Google, ARM and many other SoC/device vendors have put many efforts hardening the security of Android, including its kernel, which is (in most cases) the last defense against attack.
As a group of Android gurus focusing on rooting, we probably facing these defense more than researchers in other fields. In this post we are going to summarize kernel exploit mitigations appeared in the recent 2 years, and sharing our opinions on their effectiveness.
Note that we are going to focus on the implementation of mitigations in this post. We may point out its weakness, but we are not going to detail bypassing techniques for each mitigation.
Outline
- Hardware
- Google/Linux
- Vendors
- Samsung
- Others
Hardware
As Intel has officially abandoned its Atom product line, no one is going to challenge ARM’s Android dominance soon enough. We will be focusing on ARM for the rest part of this post, since no one cares any other architecture for Android :p
MMU
Modern ARM processors come with a comprehensive MMU, providing basic V2P translation, access control, TLB, ASIDs and many other memory management features. Among them, both 32-bit (arm) and 64-bit (arm64) mode of recent ARM architectures provide full RWX access control on pages level. In addition, one of the key “advanced” security features is PXN (Privilege Execute-Never), a feature with similar idea of Intel’s SMEP but different in implementation details. PXN has been widely enabled on 64-bit devices as a relief of ret2usr attacks.
Details on how Android kernel utilize these features will be discussed in further sections.
TrustZone
TrustZone is an extension to ARM cores, which creates two “worlds”. The following figure describes how this works: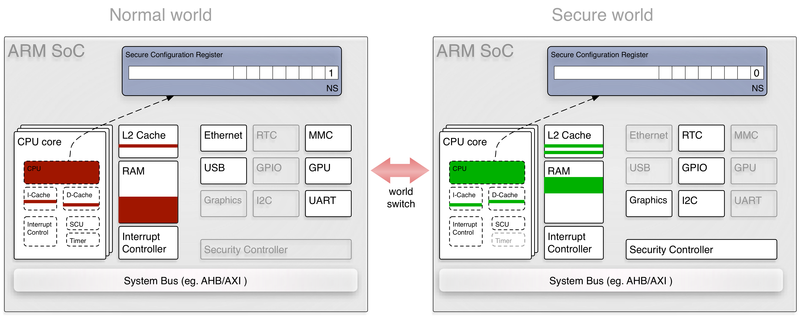
Source: https://genode.org/documentation/articles/trustzone
Although few restrictions are there that how vendor can utilize Trustzone, usually the feature-rich OS, aka Android, in our case, is going to run in the normal world. The secure world will be hosting trustlets on a light-weight OS.
As a secure world running in parallel with the normal world, compromising the kernel in normal world shall not affect the secure world if the implementation was properly done, as their communication is handled by the privileged monitor mode code usually loaded by low-level bootrom. However, there are cases seen that secure world can also be compromised due to its own bug or bugs in monitor mode.
Google/Linux
As the open source software being used most widely, Linux kernel can be modified by many parties, which not all of these modifications are merged into mainline. Here we will be only discussing the features implemented in mainline and appear in Google’s Android kernel repositories.
Linux kernel has utilized many features to harden the kernel. One of them is protecting critical memory zones like kernel text and non-volatile data. Recent Linux mainline kernel has this feature implemented through CONFIG_DEBUG_RODATA:
CONFIG_DEBUG_RODATA
arm
prompt: Make kernel text and rodata read-only
type: bool
depends on: ( CONFIG_MMU && ! CONFIG_XIP_KERNEL ) && ( CONFIG_CPU_V7 )
defined in arch/arm/mm/Kconfig
found in Linux kernels: 3.19, 4.0–4.6, 4.6+HEAD
Help text:
If this is set, kernel text and rodata memory will be made read-only, and non-text kernel memory will be made non-executable. The tradeoff is that each region is padded to section-size (1MiB) boundaries (because their permissions are different and splitting the 1M pages into 4K ones causes TLB performance problems), which can waste memory.
arm64
prompt: Make kernel text and rodata read-only
type: bool
depends on: (none)
defined in arch/arm64/Kconfig.debug
found in Linux kernels: 4.0–4.6, 4.6+HEAD
Help text:
If this is set, kernel text and rodata will be made read-only. This is to help catch accidental or malicious attempts to change the kernel's executable code.
If in doubt, say Y
Note that despite having “DEBUG” in its name, this is actually recommended for arm64. It should be enabled by default for arm also.
During kernel boot, in init/main.c, kernel_init() will call mark_rodata_ro() to literally mark every read-only section with proper permissions:
1 | static int __ref kernel_init(void *unused) |
Function mark_rodata_ro() will do nothing if CONFIG_DEBUG_RODATA is not defined:
1 |
|
If it is defined, though, the implementation of mark_rodata_ro() will be architecture specific, which means you should be looking for its definition in arch/arm and arch/arm64. For both architectures, Linux kernel leverages “section” page entry to improve performance and reduce memory profile of the page table for kernel virtual address space. A “section” page entry usually is one level up than actual page entry (which represents 1 page). Doing so will allow MMU to walk the page table faster by reducing the depth and make TLB more efficient, as there are far fewer entries to be cached. This does come with a cost though, that sections must be aligned at MiB level (1MB or 2MB), which means some physical RAM can be wasted. Of course, this is a minor problem for modern devices as many of them has more than 2GB of RAM.
You may have noticed that the kernel versions mentioned above are far beyond common versions we seen in Android (3.19+ vs. 3.4/3.10/3.18). However, since the patch is really simple, Google and other vendors actively back-port these features to their own kernel repositories. This also caused some chaos that the actual code varies among different vendors, but eventually they are just doing the same stuff, which sets up the page table entries for kernel virtual address space.
For arm, a section page entry means a first-level section type PMD (folded up). Per ARM definition, the 2nd bit of the entry indicates whether it is a conventional entry or a section one. Note that super-section is not utilized here.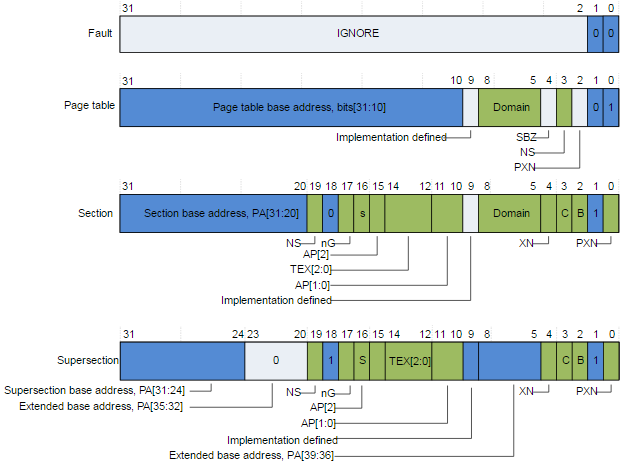
Origin: http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.dai0425/BABCDECH.html
The bit AP[2], aka APX, together with AP[1:0], will determine both user and privileged permissions:
APX AP[1:0] Privileged User 0 b00 No access No access 0 b01 Read/write No access 0 b10 Read/write Read-only 0 b11 Read/write Read/write 1 b00 – – [ 1 b01 Read-only No access ] 1 b10 Read-only Read-only 1 b11 Read-only Read-only
Source: http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.ddi0211k/Caceaije.html
So for any kernel text/rodata section, it will be APX:=1 and AP[1:0]:=b01. This is defined in mainline code in arch/arm/mm/init.c:
1 |
|
For arm64, there is a difference that by default it has a 3-level page table. This is for the apparent reason that the virtual address space is much bigger. So for now section (while still being PMD) is now a second-level one. Sometimes it is also called a “block”. The attributes available for a block are: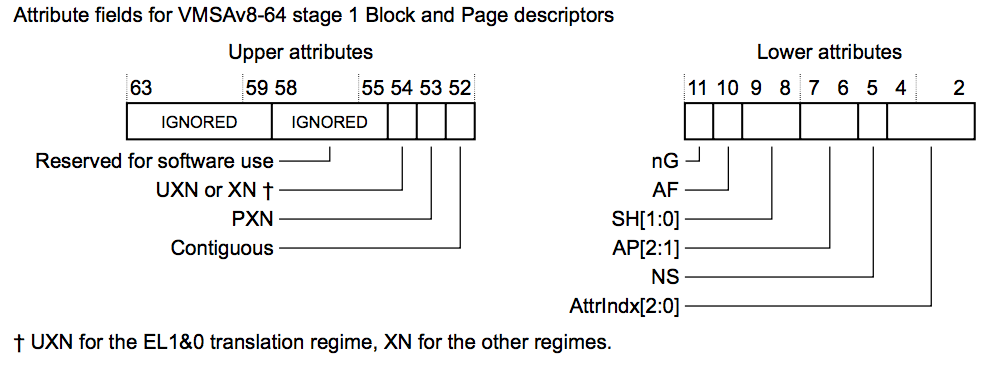
Source: http://armv8-ref.codingbelief.com/en/chapter_d4/d43_3_memory_attribute_fields_in_the_vmsav8-64_translation_table_formats_descriptors.html
It has only two bits for access permissions, noted as AP, and the mapping is simpler than arm:
AP Unprivileged (EL0) Privileged (EL1/2/3) 00 No access Read and write 01 Read and write Read and write 10 No access Read-only 11 Read-only Read-only
Source: http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.den0024a/BABCEADG.html
It is quite clear that we need to set AP[1] for read-only. So we have the following code in arch/arm64/mm/mmu.c:
1 |
|
One attack against kernel read-only protection is to modify the kernel page table and change the permission of corresponding entries. This requires a bug which may lead to kernel write, controlled bit flip or code execution. Note that Samsung has TrustZone/Hypervisor components which protects the page table, which will be discussed in later sections. Info-leak is not needed in this case since the “template” of kernel page table is a static object determined at link time. The location is assigned to init_mm as its initial value in mm/init-mm.c:
1 | struct mm_struct init_mm = { |
The value of swapper_pg_dir varies from arch to arch. For both arm and arm64, they are defined in head.S. For arm:
1 |
|
And for arm64:
1 |
|
So for these two architectures, it starts at 4 pages and 3 pages ahead of kernel text prespectively. Kernel text starts relatively at a fixed location for most of the devices (or at least for specific SoCs), so we can predict the beginning of this critical kernel data structure.
Besides CONFIG_DEBUG_RODATA, PXN is also a very important security feature which has been enabled in recent kernel versions. By the time Android L was released, PXN has been enabled on all arm64 devices. Note that PXN bit also presents in arm32 since ARMv7, but seldomly used.
PXN on arm64 was introduced into Linux kernel by commit 8e620b0476696e9428442d3551f3dad47df0e28f (https://kernel.googlesource.com/pub/scm/linux/kernel/git/jic23/iio/+/8e620b0476696e9428442d3551f3dad47df0e28f). It basically set PXN bit on every permission templates for user-space, as well as UXN/PXN bits for non-executable pages. This makes sure that every user-space page is mapped with PXN bit set, which mitigates ret2usr attack:
-#define PAGE_NONE _MOD_PROT(pgprot_default, PTE_NG | PTE_XN | PTE_RDONLY)
-#define PAGE_SHARED _MOD_PROT(pgprot_default, PTE_USER | PTE_NG | PTE_XN)
...
-#define PAGE_KERNEL_EXEC _MOD_PROT(pgprot_default, PTE_DIRTY)
+#define PAGE_NONE _MOD_PROT(pgprot_default, PTE_NG | PTE_PXN | PTE_UXN | PTE_RDONLY)
+#define PAGE_SHARED _MOD_PROT(pgprot_default, PTE_USER | PTE_NG | PTE_PXN | PTE_UXN)
+#define PAGE_SHARED_EXEC _MOD_PROT(pgprot_default, PTE_USER | PTE_NG | PTE_PXN)
...
+#define PAGE_KERNEL_EXEC _MOD_PROT(pgprot_default, PTE_UXN | PTE_DIRTY)
-#define __PAGE_NONE __pgprot(_PAGE_DEFAULT | PTE_NG | PTE_XN | PTE_RDONLY)
-#define __PAGE_SHARED __pgprot(_PAGE_DEFAULT | PTE_USER | PTE_NG | PTE_XN)
...
-#define __PAGE_READONLY_EXEC __pgprot(_PAGE_DEFAULT | PTE_USER | PTE_NG | PTE_RDONLY)
+#define __PAGE_NONE __pgprot(_PAGE_DEFAULT | PTE_NG | PTE_PXN | PTE_UXN | PTE_RDONLY)
+#define __PAGE_SHARED __pgprot(_PAGE_DEFAULT | PTE_USER | PTE_NG | PTE_PXN | PTE_UXN)
...
+#define __PAGE_READONLY_EXEC __pgprot(_PAGE_DEFAULT | PTE_USER | PTE_NG | PTE_PXN | PTE_RDONLY)
Just like those read-only bits, PXN can also be disabled. But keep in mind that PXN bits are set in user virtual address space, which means they are dynamically allocated, so unlike kernel ones, you will need a good kernel read bug to locate the entry to be manipulated. Usually with both read and write, there is really no need of code execution. So this is not very practicable in real exploit.
Vendors
Samsung
Samsung has been a pioneer in terms of Android security hardening for the past years. It was actively involved in enabling SELinux (SEAndroid) for Android, implementing multiple security hardening in kernel and invented the KNOX Active Protection, which is the first TrustZone (TIMA) /Hypervisor based active protection for kernel.
Taking kernel module as an example, since Galaxy S4 (or maybe even earlier), Samsung has implemented lkmauth (loadable kernel module authentication) based on TIMA (TrustZone based Integrity Measurement Architecture). For each kernel module get loaded, getting root privilege is not enough, which the kernel module itself will go through a mandatory digital signature verification happens in TrustZone instead of normal world OS. This means even though an attack can compromise kernel and gain arbitrary read/write, he/she can still not load any kernel module for convenient kernel code execution.
However, lkmauth still had its weakness, which was pointed out in multiple public sessions, including:
- Advanced Bootkit Techniques on Android, Zhangqi Chen & Di Shen, SyScan360 2014
- Adaptive Android Kernel Live Patching, Tim Xia & Yulong Zhang, HITBSecConf 2016
It was pointed out that patching the code of lkmauth() itself can successfully bypass the logic and allow kernel module to be loaded. It’s actually a problem about the trusted computing basee is not really trustworthy (kernel text can be compromised). Samsung has fixed this weakness since Galaxy S5, by introducing TIMA protected page table and read-only kernel text/data into the kernel. It was a surprise that this weakness got mentioned again in the latter session in 2016. Per the slides, the device demonstrated was a Galaxy S4, which may explain why lkmauth() can still be patched.
Besides kernel module authentication, Samsung has enforced KNOX Active Protection (KAP) since 5.1.1 ROMs for Galaxy S6/S6 Edge. This seems to be a reaction to the release of PingPong root. In that version of KAP, Samsung did not only protect the page table, but also put crucial kernel objects like credentials into consideration. For example, a dedicated cache (kmem_cache) is created for credential objects, which all pages assigned to the cache are marked as read-only for kernel. In kernel/cred.c:
1 | void __init cred_init(void) |
The cred_ctor() and sec_ctor() are dummy constructor routines to make sure that the RO cred/security caches are not merged (SLUB merge) with other caches. The cache names are critical here since it has been hard coded in SLUB implementation. In mm/slub.c:
1 |
When the two “_ro” caches are create, the underlying implementation of kmem_cache_create, allocate_slab, is also modified to assign dedicated pages to the read-only caches:
1 | static struct page *allocate_slab(struct kmem_cache *s, gfp_t flags, int node) |
With the pages read-only to kernel, any allocation/modification of these objects must be done through calling the hyp component. This helps mitigating conventional DKOM exploit. So far, this is the most efficient mitigation we’ve seen in Android. The best choice of bypassing this might be code-reuse attack, however, can still be further mitigated through validating in tz/hyp.
Besides these “high-end” mitigations, Samsung also customized some syscalls to restrict post-exploit activities. Taking fork/execve as an example. These two are basically the underlying syscalls behind “system”, a very common routine an exploit will utilize after privilege escalation. So Samsung added some additional check in execve (fs/exec.c):
1 | SYSCALL_DEFINE3(execve, |
For any root process, sec_restrict_fork() will check if it is originated from /data. In general, this directory is the only place that an user application can start in. Samsung is hoping that this can stop rooting applications from spawning new process, in most cases a daemon running as root. But since they failed to protect some critical data structures being used inside sec_restrict_fork(), bypassing this check if far easiler than bypassing a tz/hyp assisted protection.
Others
Some mitigations were also seen on other manufacturers of Android devices. Besides system partition write protection, which seems to be the favourite of most vendors, a lot of efforts are also done to prevent devices from being rooted. The most ineffective way we have seen is to setup inotify on certain files, like /system/xbin/su. Simply killing the notifier is going to workaround this. But recently we’ve seen something more interesting from YunOS, a customized Android ROM from Alibaba.
One of the generic route we take for rooting is by modifying the addr_limit of current task’s thread_info structure. This allows the kernel to take the whole virtual address space (or sometimes just enough virtual address space) as “USER_DS” so read/write operation in the address range won’t be restricted for certain syscalls, like pipe_read and pipe_write. In the kernel of YunOS, we noticed the following code in el0_svc_naked: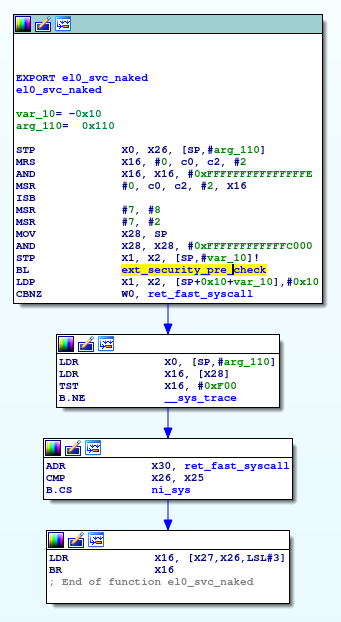
The symbol el0_svc_naked is the entry of syscall of Linux on arm64. YunOS added one additional ext_security_pre_check before actually heading into the syscall. Apparently something is checked there. The function looks like this:
The first basic block extracts addr_limit from current context and check against the standard USER_DS value, 0x8000000000 (1 << 39). If it is not the desired value, it will enforce a SIGKILL to the calling process. Since SIGKILL can’t be masked, the calling process will be forcibly killed (which may lead to a panic if in the middle of exploit). This is by far the most effective exploit mitigation without tz/hyp assistance. Howevr, it can’t stop the following two scenarios:
- One vulnerabilities or a set of vulnerabilities for direct kernel read/write
- Pure code-reuse attack
Vulnerabilities leads to direct kernel read/write are quite hard to find now, but the latter one is still achievable. Besides commit_cred, there are still quite some routines can be used conveniently to modify credential of a task. By controlling a certain function entry with 1 or 2 argument would be more than enough.